
One of the most important milestones in computing was figuring out how to keep data alive after a program stops. In the beginning, both the code and the data lived in memory. If the program crashed, the data disappeared too. That’s why engineers created file systems, so data could be saved on disk and loaded again later. For small programs, this worked fine. But as systems grew (think of train schedules or payroll software) people needed better ways to store and manage data. That’s when SQL came in.
SQL is still everywhere today. It powers databases like Postgres and MySQL, but also shows up in tools like New Relic with its own version NRQL, or Salesforce with SOQL.
Common Criticisms of SQL
SQL is dying
SQL remains a backbone of data persistence in most industries.
SQL doesn’t work well with Node.js
Node.js is asynchronous by nature, while many SQL libraries are synchronous. This can create friction, but modern tools like PostgreSQL clients with pooling or asynchronous ORMs address this.
SQL is slow
Poorly written queries can be slow but that’s not SQL’s fault. With proper indexing, caching, and query design, SQL can be incredibly fast.
Free Resources to Refresh Your SQL Knowledge
- Microsoft SQL fundamentals: This is a long, theory-based course, but it provides a solid foundation for understanding SQL concepts.
- Codecademy: An interactive approach, Codecademy saved me a lot of time when I started learning how to program, same for SQL.
- W3Schools SQL Tutorial: This one is interactive but is more for consulting syntax and patterns.
- SQLBolt: Interactive and theory basis, good option.
- Khanacademy SQL: Interesting approach practice & theory focused for web development.
Should you use an ORM?
First, what’s an ORM?
ORM(Object-relational mapping) lets you work with the database using code instead of writing SQL directly. It’s helpful when you want to avoid thinking about SQL or when your data model is simple. But ORMs aren’t perfect. For complex queries or performance-heavy parts of your app, they can get in the way. They sometimes generate SQL that’s hard to control or debug.
That’s why in this series, I’ll show a SQL query approach, some folks are inclined to use a more raw SQL approach instead an ORM.
Installing PostgresSQL using Docker compose
Docker is an excellent tool to avoid bringing garbage to our computers, you can easily install any package and use it as a local service as we will use postgres. Install docker using this link guidelines Download & install Docker the suitable for OS type.
In this post I will use the PostgreSQL database to start creating our CRUD of Note entity, the docker image package is on the postgres_registry. The docker-containers will be managed with Docker Compose, which requires creating a compose.yml file.
Friendly reminder: All code snippets here are illustrative, you can find the complete code in the adaptable-backend-nodejs-persistence repository.
services: postgres: image: postgres:17-alpine environment: POSTGRES_PASSWORD: postgres POSTGRES_USER: postgres TZ: America/Bogota PGTZ: America/Bogota networks: - adaptable_backend_nodejs volumes: - postgres_data:/var/lib/postgresql/data ports: - 5432:5432 healthcheck: test: ["CMD-SHELL", "pg_isready"]
networks: adaptable_backend_nodejs:
volumes: postgres_data:We are defining our first service postgres which use the 17 version, set the variables POSTGRES_USER and POSTGRES_PASSWORD for credentials and TZ & PGTZ for timezone handling. Added networks to keep the application isolated, in case you have running other local services, volumes to keep the persistency even if we restart the machine, ports to forward to host machine (ours) and healthcheck command that postgres docker image provides to guarantee the service ran successfully and ready for connections.
Running the postgres service
To check if the service are working, lets add a new command to package.json scripts to make an alias and avoid type the whole command:
"scripts": { ... "prepare:dev": "docker compose up -d --wait",},then run:
npm run prepare:devCheck if the logs are not telling any error or so, go to docker desktop interface and look for the log:
2025-07-25 12:16:55 2025-07-25 17:16:55.792 UTC [1] LOG: database system is ready to accept connectionsThen you are ready for start building.
Integrate PostgreSQL to our node.js project
Following the guidelines of the project, the database stuff will reside inside core/database folder with the purpose of handling all persistence layer there. To begin, install the connector library for postgres, I will use pg minimal, is good maintained and provide the majority of tools required.
npm i pgnpm i -D @types/pgIn the ER-diagram all entities have in common 3 attributes, id, created_at, and updated_at for that reason I am going to create inside core/database the BaseEntity.ts
export class BaseEntity { id: string | number; createdAt: Date; updatedAt: Date;}The id can be string or number to make it flexible in case you want to use a sequence for integers or string for a hash or uuid values. createdAt & updatedAt will be dates stores for metadata proposal. Then lets create the repository interface that can be implemented several technologies.
Repository pattern
For many years I’ve seen numerous debates about ORM, Doctrine, DAO and other persistence pattern, one of the most adaptable and applicable patterns for several use cases is the Repository Pattern, which basically tells the application’s controllers, “I will take care of persistence” You do your business things. That’s powerful and alleviate the entire application of handling a particular technology.
Creating the interface IRepository.ts
import {BaseEntity} from "@core/database/BaseEntity";
export type AutoGeneratedFields = keyof BaseEntity;export type CreatePayload<T, EntitySpecificOmittedKeys extends keyof T = never> = Omit<T, AutoGeneratedFields | EntitySpecificOmittedKeys>;export type UpdatePayload<T, EntitySpecificOmittedKeys extends keyof T = never> = Partial<CreatePayload<T, EntitySpecificOmittedKeys>>;
export interface IRepository<Entity extends BaseEntity> { findById(id: string | number): Promise<Entity | null>; findAll(): Promise<Entity[]>; create(data: Partial<Omit<Entity, AutoGeneratedFields>>): Promise<Entity>; update(id: string | number, data: Partial<Omit<Entity, AutoGeneratedFields>>): Promise<Entity | null>; delete(id: string | number): Promise<boolean>; closeConnection(): Promise<void>;}- AutoGeneratedFields contains the type definition of BaseEntity them are obtained using the keyof operator
- CreatePayload are defined with the generic T, which will be the Entity we will use in the application, EntitySpecificOmittedKeys will contains the definition of the entity wit the omited keys like AutoGeneratedFields for internal usage, it its assigned a Omit operator given T as the replaced generic entity and AutoGeneratedFields or another generic EntitySpecificOmittedKeys specified.
- UpdatePayload is similar to CreatePayload but it uses a Partial operator in favor an entity can not require to update the entire data.
In the interface IRepository we are creating the contract the most defined possible, typescript has their own limitations regarding OOP so I will try to stay closer to fundamentals and make the repository suitable for technologies, which does not mean we can extend in the future, that’s the beauty of good design, be extendable. The majority of methods at IRepository are suitable for a CRUD, the only rare is closeConnection(), that will be useful for testing and reduce database loads. To avoid hardcoding things lets create the databaseEngine.ts, we will add many engines as we need, our current scope is to add postgres for SQL and mongo for NoSQL.
export enum DatabaseEngine { NOSQL = "mongodb", SQL = "postgres"}Adding the database environment variables
As we did in compose.yml file, we need to update our .env to load that configuration, add the variables:
TZ=America/Bogota
# Database SQLDATABASE_URL=postgresql://postgres:postgres@localhost:5432/postgresDATABASE_ENGINE=postgresshould be match with the values present in the compose.yml environment section.
- TZ: Will be set the timezone, ideally for timestamps and synchronization present in futures posts.
- DATABASE_URL: A preparation of database url to connect with postgres locally.
- DATABASE_ENGINE: Used to discriminate between a type of database and others.
Next steps is to add it into our configuration file
// shorten for brevityinterface EnvConfig { NODE_ENV: "development" | "production" | "test"; PORT: number; TZ: string; DATABASE_URL: string; DATABASE_ENGINE: string;}
// shorten for brevity
private readonly envSchema: Record<keyof EnvConfig, EnvVarConfig> = { NODE_ENV: { required: true, type: "string" }, PORT: { required: true, type: "number" }, DATABASE_URL: { required: true, type: "string" }, DATABASE_ENGINE: { required: true, type: "string" }, TZ: { required: false, type: "string", defaultValue: "America/Bogota" } };...Create the SQL setup
As we talk earlier about ORM and other patterns to create the SQL database infra exists other tools to handle schemas and tables updates commonly named as migrations which basically keep a tracking of changes and guarantee certain frictions between a release. In my opinion those migration tools like liquidbase or flyway are overkill, having them does not guarantee your migrations are running well or have frictions further, them deviated of the things that really matter: Write skilled SQL code.
I will adopt a more conservative approach without sacrifice simplicity and scalability, REAL scalability. Lets create our first migration file in raw postgres sql:
--- Creating table notes
BEGIN;
DO $$BEGIN CREATE TABLE IF NOT EXISTS notes ( id SERIAL PRIMARY KEY NOT NULL, content VARCHAR(255) NOT NULL, times_sent INT NOT NULL DEFAULT 0, created_at TIMESTAMPTZ NOT NULL DEFAULT CURRENT_TIMESTAMP, updated_at TIMESTAMPTZ NOT NULL DEFAULT CURRENT_TIMESTAMP ); EXCEPTION WHEN OTHERS THEN ROLLBACK; RAISE;END $$;
COMMIT;I created inside DO $$/END $$; statement th declaration to create a table, using the idempotence property create the table notes if not exist. Added the required fields with the particularity of timestamps will be set using a local timezone, which will be useful for deployments reasons later. The statement also allow to catch any exception if there’s any error with the table creation, in case failure, rollback. In next articles we will deep dive into the transactions.
Running migrations
Having our first migration file, next step is to run in a database, you can use any postgres client available in the market, free or paid, your decision. For simplicity lets create a script that will read migrations folder and run each one.
import { readdirSync, readFileSync } from "fs";import { resolve } from "path";import { Client } from "pg";
import { config } from "src/core/configuration/configuration";
export class Migrate { private static MIGRATIONS_FOLDER = "src/core/database/sql/migrations"; private static readonly MIGRATIONS_PATH = resolve(process.cwd(), Migrate.MIGRATIONS_FOLDER);
static async run() { const dbConnection = new Client({ connectionString: config.get("DATABASE_URL"), }); console.log("Running migrations... "); const files = readdirSync(Migrate.MIGRATIONS_PATH);
try { await dbConnection.connect();
for (const file of files) { console.log(`Running migration: ${file}`); const fileContent = readFileSync(`${Migrate.MIGRATIONS_PATH}/${file}`, "utf8"); const result = await dbConnection.query(fileContent); console.log("result query: ", result); } } catch (error) { console.error("error in migrate: ", error); } finally { await dbConnection.end(); } }}
Migrate.run();We created a Migrate class and static method run() to read migrations folder, stablish connection with database passing the DATABASE_URL previously configured. It will iterate to all files sorted ascendent by default (That’s why the prefix number name 001_) and execute all of them. When finish, close the connection. For command handy easier, let’s add a new command to scripts section.
"scripts": { ... "prepare:dev": "docker compose up -d --wait", "migrate": "NODE_OPTIONS=--no-warnings npx ts-node -r tsconfig-paths/register src/core/database/sql/migrate.ts"},We are running the migrate.ts file without needed to transpile by using ts-node and tsconfig-paths/register to match with the imports policy.
Running npm run migrate you should not see any error, then using the client of your preference you can see the table created. I used the built-in database plugin of webstorm jetbrains editor.
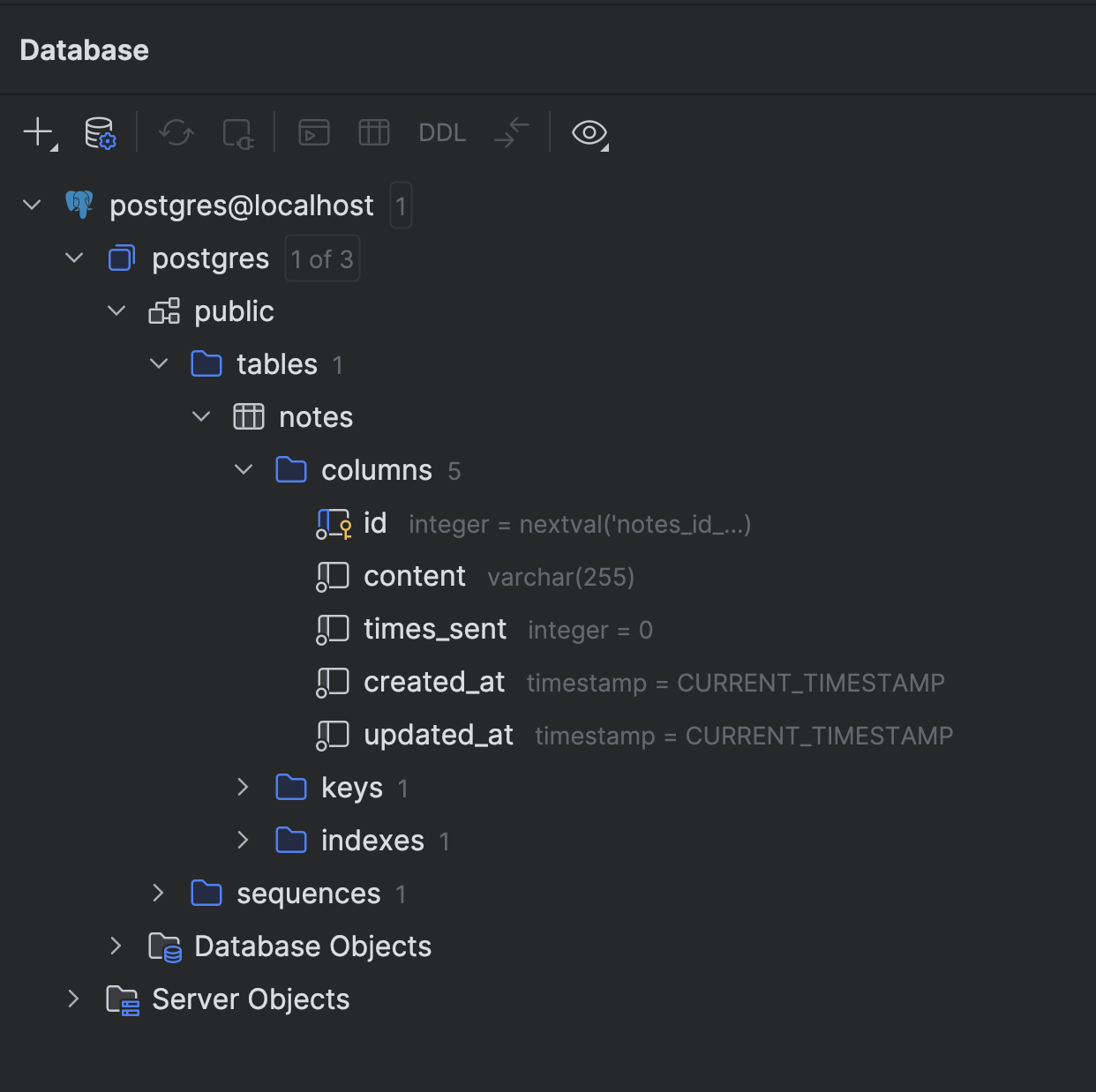
Creating the seeders
You can add data as you can to store some values, but, we want to automate it as much we can, then lets replicate the idea of Migrate class but lets name it Seeder. Lets add a seeder folder to keep all sample data:
INSERT INTO notes (content)VALUES ('The only limit to our realization of tomorrow is our doubts of today.'), ('Do what you can, with what you have, where you are.'), ('The best way to predict the future is to invent it.');We will create the script that will run all seeders:
import { readdirSync, readFileSync } from "fs";import { resolve } from "path";import { Client } from "pg";
import { config } from "src/core/configuration/configuration";
export class Seeder { private static SEEDER_FOLDER = "src/core/database/sql/seeders"; private static readonly SEEDER_PATH = resolve(process.cwd(), Seeder.SEEDER_FOLDER);
static async run() { const dbConnection = new Client({ connectionString: config.get("DATABASE_URL"), }); console.log("Running seeders... "); const files = readdirSync(Seeder.SEEDER_PATH);
try {
await dbConnection.connect();
for (const file of files) { console.log(`Running seeder: ${file}`); const fileContent = readFileSync(`${Seeder.SEEDER_PATH}/${file}`, "utf8"); await dbConnection.query(fileContent); } } catch (error) { console.error("error seeding: ", error); } finally { await dbConnection.end(); } }}
Seeder.run();then lets update the script to simplify the process of seeeding
"scripts": { ... "prepare:dev": "docker compose up -d --wait", "migrate": "NODE_OPTIONS=--no-warnings npx ts-node -r tsconfig-paths/register src/core/database/sql/migrate.ts", "seeder": "NODE_OPTIONS=--no-warnings npx ts-node -r tsconfig-paths/register src/core/database/sql/seeder.ts"},Running npm run seeder the note items are stored in database, using the database plugin I see the new changes:

Implementing the SQLRepository
Now we have all the infrastructure (local, when everything runs) required to start interacting with the database, abstracting the application from all complexity that implies work with database, that’s why we are isolating in a sql folder.
import { Client } from "pg";
import { config } from "src/core/configuration/configuration";import {AutoGeneratedFields, IRepository } from "@core/database/IRepository";import {BaseEntity} from "@core/database/BaseEntity";
export class SQLRepository<Entity extends BaseEntity> implements IRepository<Entity> { private readonly tableName: string; private readonly client: Client;
constructor(tableName: string) { this.tableName = tableName; this.client = new Client({ connectionString: config.get("DATABASE_URL"), }); this.client.connect(); this.client.on("error", (error) => { console.log("Something happens: ", error); process.exit(1); }); } // shorten for brevity...}The SQLRepository will be coupled to the technology sql managed by the library pg, it implements the interface extending the generic Entity with BaseEntity, this is useful in case we need to remove/add fields, it will perform automatically. we defined 2 important attributes tableName to parametrize the name of table to write SQL and client that will handling the connection with postgres database. We receive tableName via constructor and initialize the client by getting the DATABASE_URL connection string to the client according to pg connection params. pg expose a method connect() and several EventEmitter, but our interest is on error because if the database connection fails, the entire application should fail, then we force adding exit(1), returning a error.
Write SQL code for search, create, delete or update requires special syntax where we need to specify the column names, order and type of data. As we are in a typescript stack we will receive object or DTOs from restControllers and controllers, so we need to map them into a SQL syntax, then lets create our custom mapper inside SQLRepository class:
Helper to create SQL queries
export type QueryPrepare = { columns: string; indexes: string; values: unknown[]; lastNumberKey: number;};
//shorten for brevity... private transformQueryData(data: Partial<Omit<Entity, AutoGeneratedFields>>): QueryPrepare { const keys = Object.keys(data); const values = Object.values(data); const sequence = Array.from({ length: keys.length }, (_, i) => 1 + i); const sequenceMapped = sequence.map(digit => `$${digit}`); return { columns: keys.join(","), values, indexes: sequenceMapped.join(","), lastNumberKey: keys.length, }; }//shorten for brevity...The private method transformQueryData() receive a data object that explicitily has been ignored the AutoGeneratedFields that will be handling in a database layer, so that can be ignored from the queries. The method returns a QueryPrepare response which contains all fields and values mapped. Lets break down the function:
- keys: As we receive a key-value pair object, to write SQL we want each keys separated
- values: an array of all values.
- sequence: To avoid SQL injection, many libraries implement the parametrized values using binding, so the number of parameters can be generated in a sequence, find more sequences
- sequenceMapped: We just added the prefix char $ to all sequence.
Create Method
Now we have our dedicated SQL helper, now we are able to write the create() method inside SQLRepository class:
//shorten for brevity... async create(data: Partial<Omit<Entity, AutoGeneratedFields>>): Promise<Entity> { const queryTransformed = this.transformQueryData(data); const sql = { text: `INSERT INTO ${this.tableName}(${queryTransformed.columns}) VALUES(${queryTransformed.indexes}) RETURNING *;`, values: queryTransformed.values, }; const result = await this.client.query(sql); return result.rows[0]; }//shorten for brevity...The create() method receive a generic data and response a Promise wit that generic entity created, use the helper function previously created to prepare the query, we start creating the INSERT statement, following of table name, columns and values. that query is passed to the client to perform the operation and return the results, previously in the query we add the RETURNING statement to return all stored.
Find methods
The findAll() method perform to retrieve all information available of the table name.
//shorten for brevity... async findAll(): Promise<Entity[]> { const sql = `SELECT * FROM ${this.tableName};` const result = await this.client.query(sql); return result.rows as Entity[]; }//shorten for brevity...The findById() method will look at the specific id if exists.
//shorten for brevity... async findById(id: string | number): Promise<Entity | null> { const sql = { text: `SELECT * FROM ${this.tableName} WHERE id=$1;`, values: [id], }; const result = await this.client.query(sql); return result.rows[0]; }//shorten for brevity...Update method
A SQL update requires similar work as we did at create(), at this case we should to concatenate lastIndex and id to continue the approach of avoiding SQL injection using binding parameters.
//shorten for brevity... async update(id: string | number, data: Partial<Omit<Entity, AutoGeneratedFields>>): Promise<Entity | null> { const queryTransformed = this.transformQueryData(data); const lastIndex = `$${queryTransformed.lastNumberKey+1}`; const sql = { text: `UPDATE ${this.tableName} SET ${queryTransformed.columns} = ${queryTransformed.indexes}, updated_at = DEFAULT WHERE id=${lastIndex} RETURNING *;`, values: queryTransformed.values.concat(id), }; const result = await this.client.query(sql); return result.rows[0]; }//shorten for brevity...Delete method
The delete() method includes the id to making sure we are deleting the proper information.
//shorten for brevity... async delete(id: string | number): Promise<boolean> { const sql = { text: `DELETE FROM ${this.tableName} WHERE id=$1 RETURNING *;`, values: [id], }; const result = await this.client.query(sql); return result.rows[0] || false; }//shorten for brevity...Creating the NoteRepository
After create all infraestructure for SQL, now from the features folder lets create the NoteRepository class that will choose a technology to use (SQL, NoSQL) based in the DATABASE_ENGINE env-var we defined earlier. Here we are creating a benefit separation between the business data layer and technologies.
export class NoteRepository implements IRepository<Note> { private DB_COLLECTION_NAME = "notes"; private repository: IRepository<Note>;
constructor() { const dbEngine = config.get("DATABASE_ENGINE");
if (dbEngine === DatabaseEngine.SQL) { this.repository = new SQLRepository<Note>(this.DB_COLLECTION_NAME); } else if (dbEngine === DatabaseEngine.NOSQL) { // To be implemented } }
findAll(): Promise<Note[]> { return this.repository.findAll(); }
create(data: CreatePayload<Note, "timesSent">): Promise<Note> { return this.repository.create(data); }
delete(id: string | number): Promise<boolean> { return this.repository.delete(id); }
findById(id: string | number): Promise<Note | null> { return this.repository.findById(id); }
update(id: string | number, data: UpdatePayload<Note, "timesSent">): Promise<Note | null> { return this.repository.update(id, data); }
closeConnection(): Promise<void> { return this.repository.closeConnection(); }}The NoteRepository class implement the IRepository contract we defined earlier, using in the constructor a Strategy Pattern to choose between a database engine to another, providing flexibility to use a technology or other. The “timesSent” parameter is a field we want to ignore at notes table, because will be managed by another process when the user wants to send by email in futures features.
Registering the NoteRepository
As we are using dependency injection, let’s register the NoteRepository in the container definition
export const container = createContainer({ injectionMode: InjectionMode.CLASSIC, strict: true,});
container.register({ /* Controllers */ noteController: asClass(NoteController).singleton(),
/* Repositories */ noteRepository: asClass(NoteRepository).singleton(),});Updating the NoteController
Now, The NoteController class is now more concrete and useful, it can interact with NoteRepository to delegate some operations. Thanks to awilix we inject the NoteRepository. Then implement all methods to complete the CRUD approach.
export class NoteController {
constructor(private noteRepository: NoteRepository) {}
public getNotes(): NoteDto[] { async getNotes(): Promise<ListNoteDto[]> { const result = await this.noteRepository.findAll(); return result.map((note: Note) => { return { id: note.id, content: note.content }; }); return [ { id: 1, content: "Hello 1 - from controller" }, { id: 2, content: "Hello 2 - from controller" }, ]; }
async createNote(payload: CreateNoteDto): Promise<void> { await this.noteRepository.create(payload); }
async updateNote(id: string | number, payload: UpdateNoteDto): Promise<void> { await this.noteRepository.update(id, payload); }
async deleteNote(id: string | number): Promise<void> { await this.noteRepository.delete(id); }}The differentiating method is getNotes() which is required to map a database entity to a specific DTO. In next articles we deep dive in mapper best practices.
Complete the NoteRestController CRUD
Before complete the CRUD lets add a common response data format that our RestAPI will use as a contract to tell to different clients (web, ios, android) the expected response object to make it predictable and follow the same convention. Lets add the responseTypes.ts file where we will add all responses types in the Rest API layer:
export class SuccessResponse<T> { data: T;
constructor(data: T) { this.data = data; }}A SuccessResponse class that receive a generic T class or object that tell to clients the response has been successfully along with HTTP status 2xx. Now, lets implement the rest of methods.
// shorten imports for brevity
@Controller("notes")export class NoteRestController { private noteController: NoteController; private static ID_PARAM_DETAIL = { name: "id", description: 'Unique identifier of note', type: String, required: true, };
constructor() { this.noteController = container.resolve("noteController"); }
@Get() @ApiOkResponse({ type: [NoteDto], description: "Get all notes", }) public getNotes(): NoteDto[] { async getNotes(): Promise<SuccessResponse<ListNoteDto[]>> { return this.noteController.getNotes(); const results = await this.noteController.getNotes(); return new SuccessResponse(results); }
@Post() @ApiOkResponse() async createNote(@Body() payload: CreateNoteDto): Promise<void> { await this.noteController.createNote(payload); }
@Put(`:${NoteRestController.ID_PARAM_DETAIL.name}`) @ApiParam(NoteRestController.ID_PARAM_DETAIL) @ApiOkResponse() async updateNote(@Param(NoteRestController.ID_PARAM_DETAIL.name) id: string | number, @Body() payload: UpdateNoteDto): Promise<void> { await this.noteController.updateNote(id, payload); }
@Delete(`:${NoteRestController.ID_PARAM_DETAIL.name}`) @ApiParam(NoteRestController.ID_PARAM_DETAIL) @ApiOkResponse() async deleteNote(@Param(NoteRestController.ID_PARAM_DETAIL.name) id: string | number): Promise<void> { await this.noteController.deleteNote(id); }}With Swagger nestjs decorators we are able to generate the proper swagger and the methods required to complete.
Testing CRUD
Finally after adding all required steps the remaining one is to run the application to see if all methods works, we will use the swagger page to test each endpoint, make sure the app is running (run npm run start:restAPI:dev) and access to /docs.
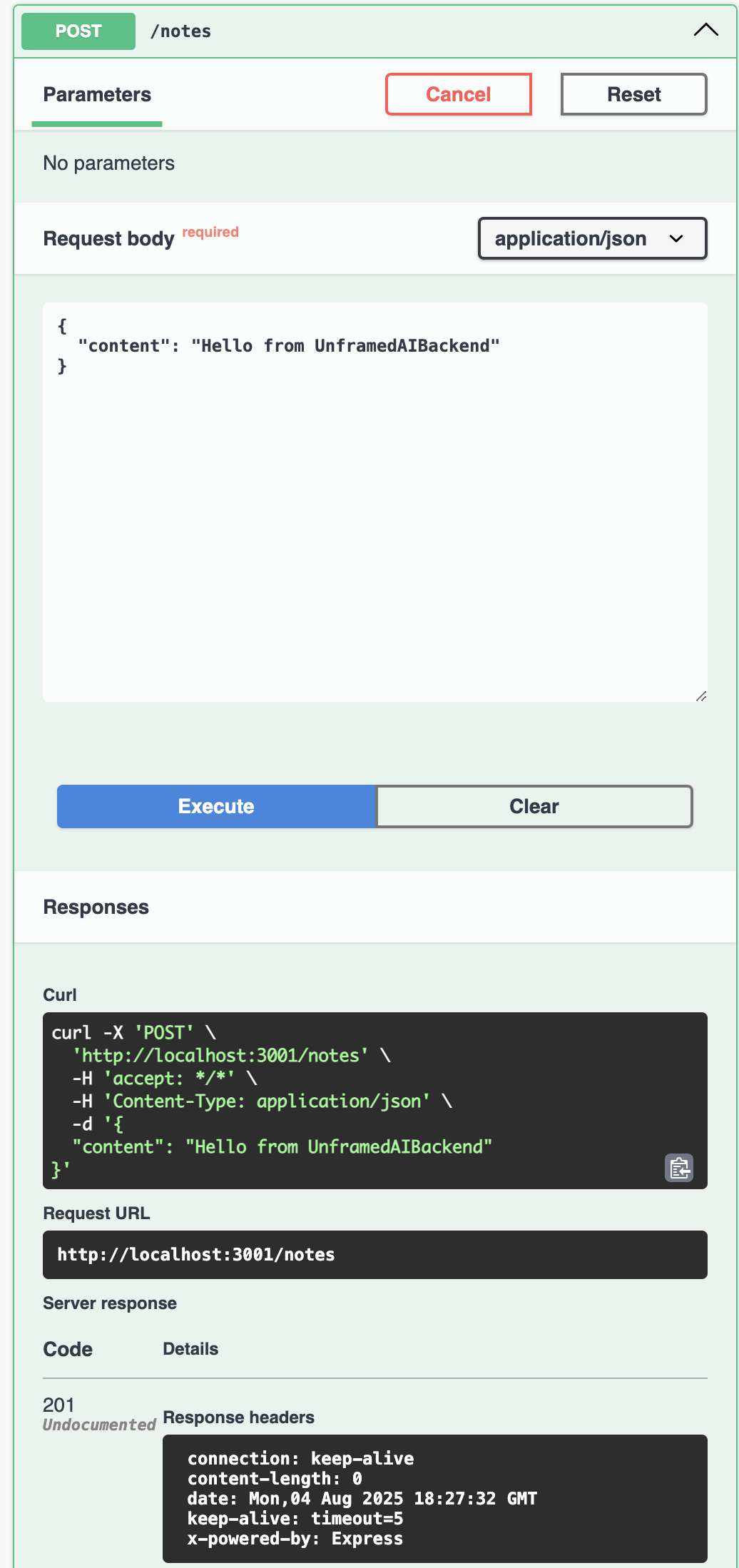
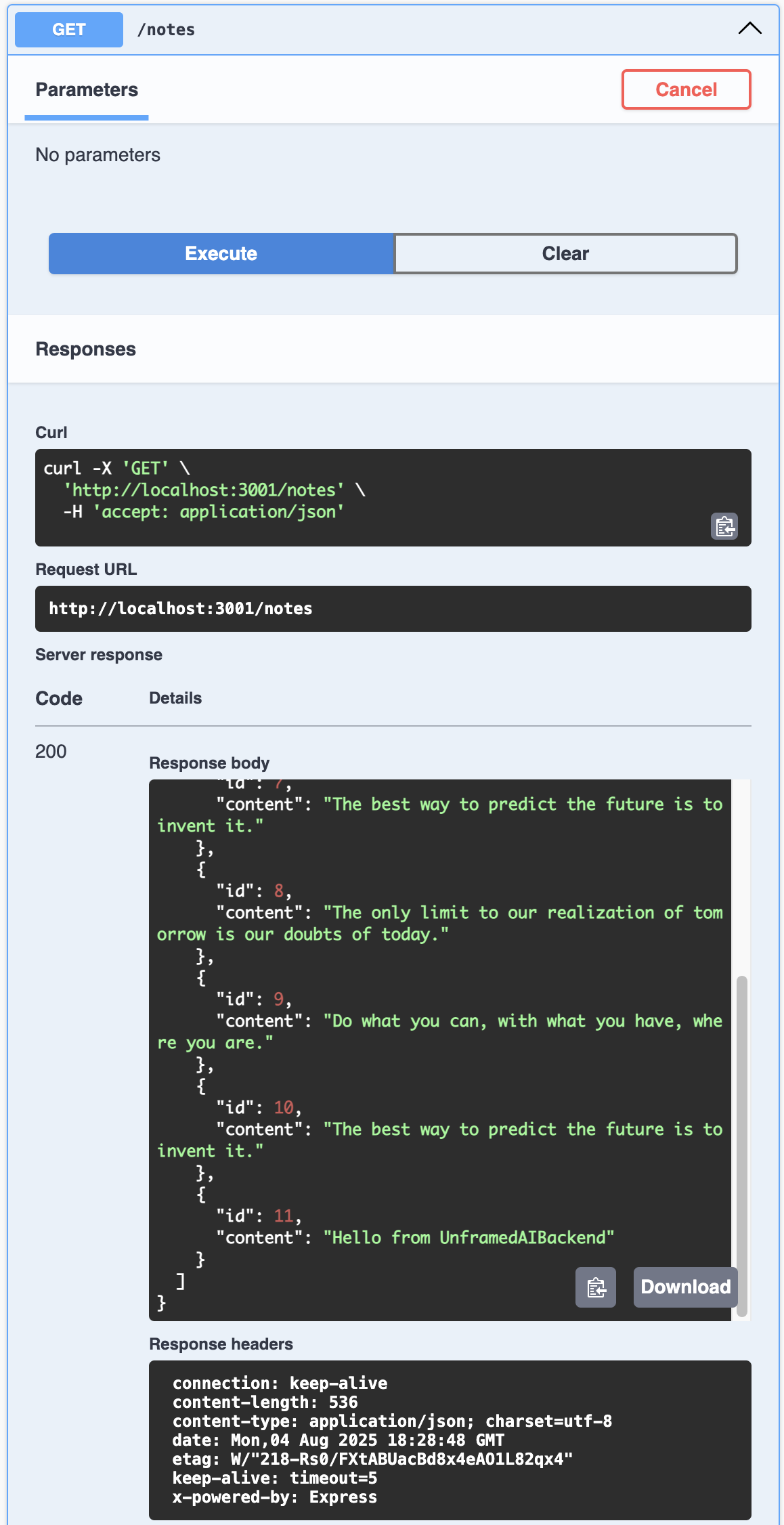
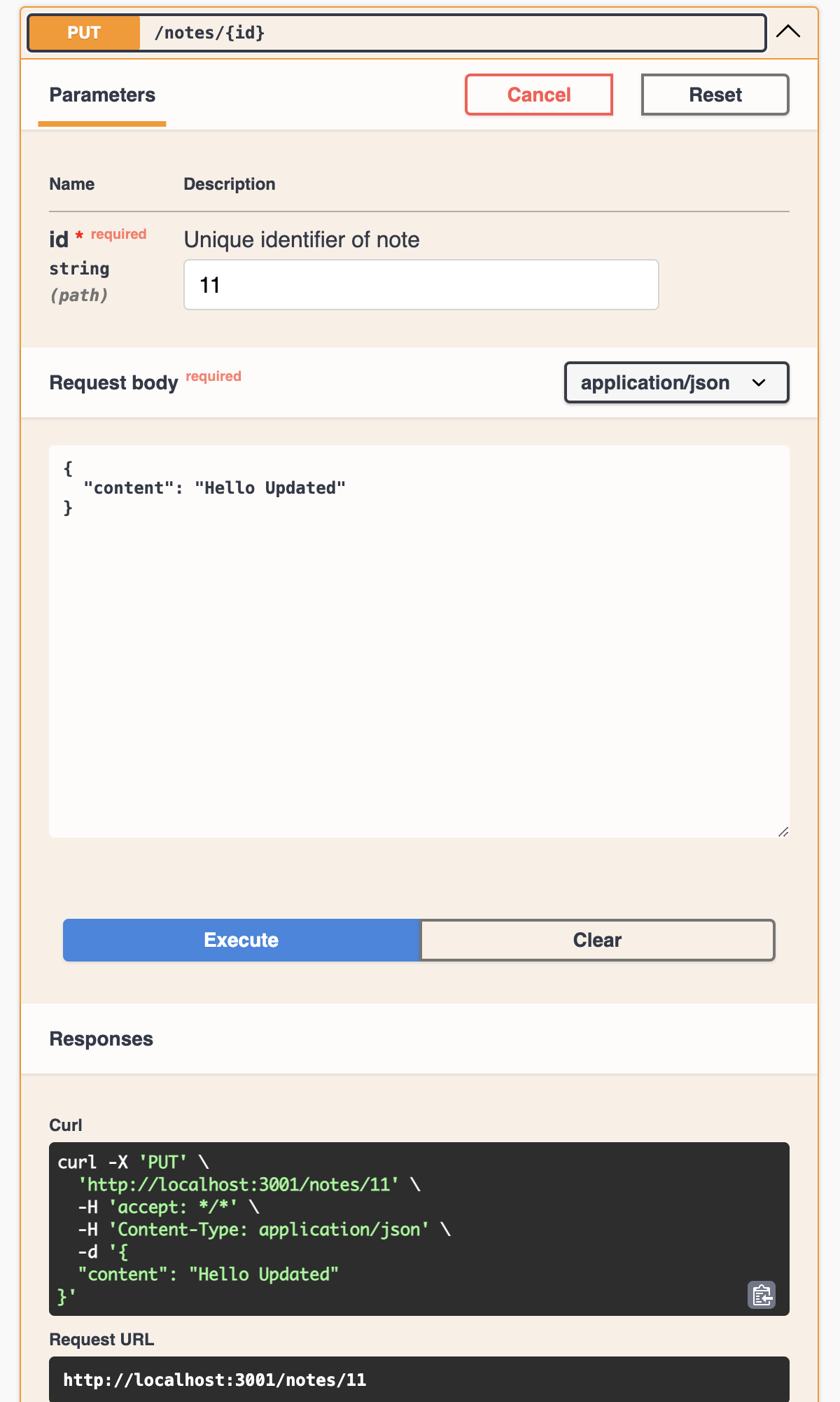
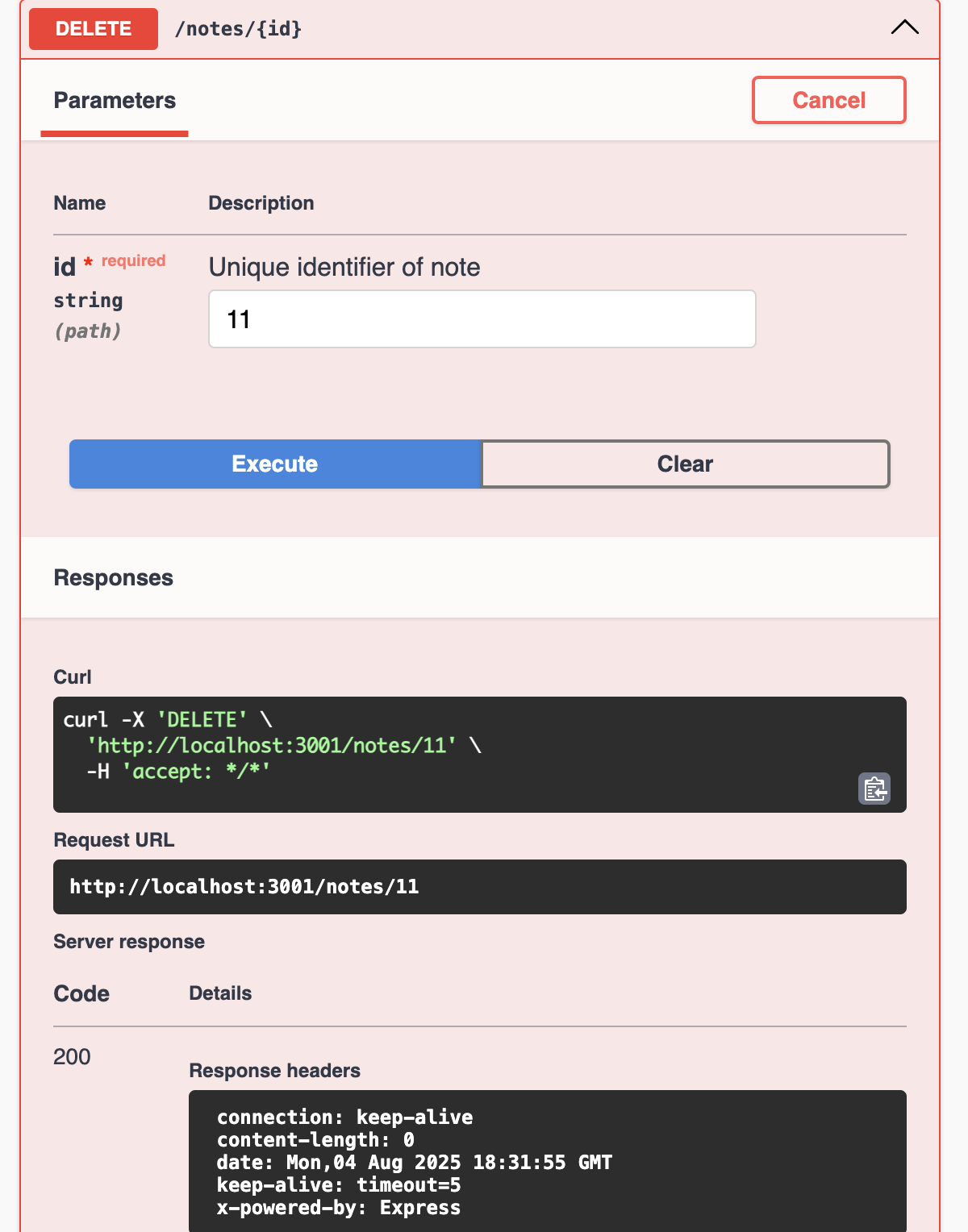
Conclusion
The persistence is a crucial part of all backend architecture, the chosen tools and type of database make bigger differences. Using best practices and classical computer science sometimes is not enough. We need to deep dive into the requirements and the needs of each project to start creating good foundations without external dependencies like ORM or Unmaintainable libraries that difficult the scalability of the backend application. Here we implement our custom ORM, everything that happens in this application is our responsibility and provide flexibility for next iterations and facilitate the switch between an engine to another thanks to interface contract and the separation of SQLRepository, in the next article we will work in switch a database engine without a dramatic refactoring session.


